文章链接:https://www.vldb.org/pvldb/vol16/p3335-butrovich.pdf
简介
本文主要魔改了Postgresql的代理工具pgbouncer。传统代理工具产生了不必要的user-kernel之间的通信,同时使用客户端连接池需要使DBMS创建更多的线程/进程。本文通过user-bypass的方法来实现一个高效率的连接代理工具Tigger,实现了最低的事务延迟(最多降低 29%)和最低的 CPU 利用率(最多降低 42%)。
背景介绍
连接放大
传统的连接方式如使用L3/L4的代理工具如Nginx或者HAProxy会产生更多的复杂性和开销,可行的方案是采用事务池化的技术(transation pooling),用户连接到Proxy,这个Proxy再和多个Client进行连接,以此实现连接复用
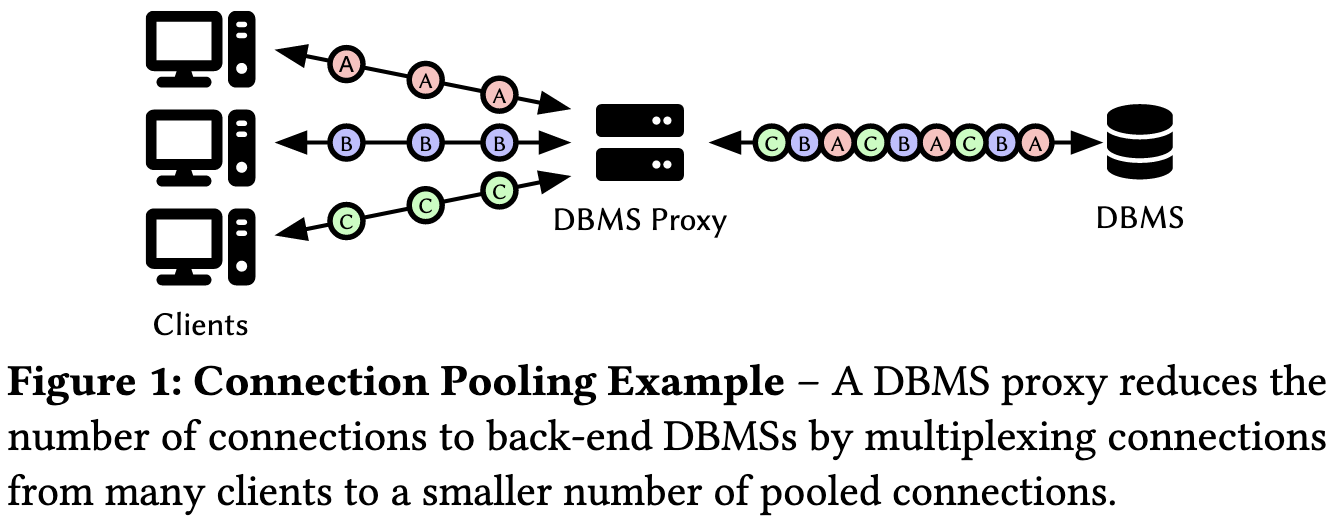
连接建立与内核数据拷贝
大多数HTTP框架的服务场景都没有使用持久化连接。短时间的连接会显著增加DBMS创建连接的CPU开销,一个经典的流程是:1.任务创建 2.创建Socket 3.TCP握手 4. TLS 5.client验证 6.查询。
这些流程产生了毫秒级的延迟
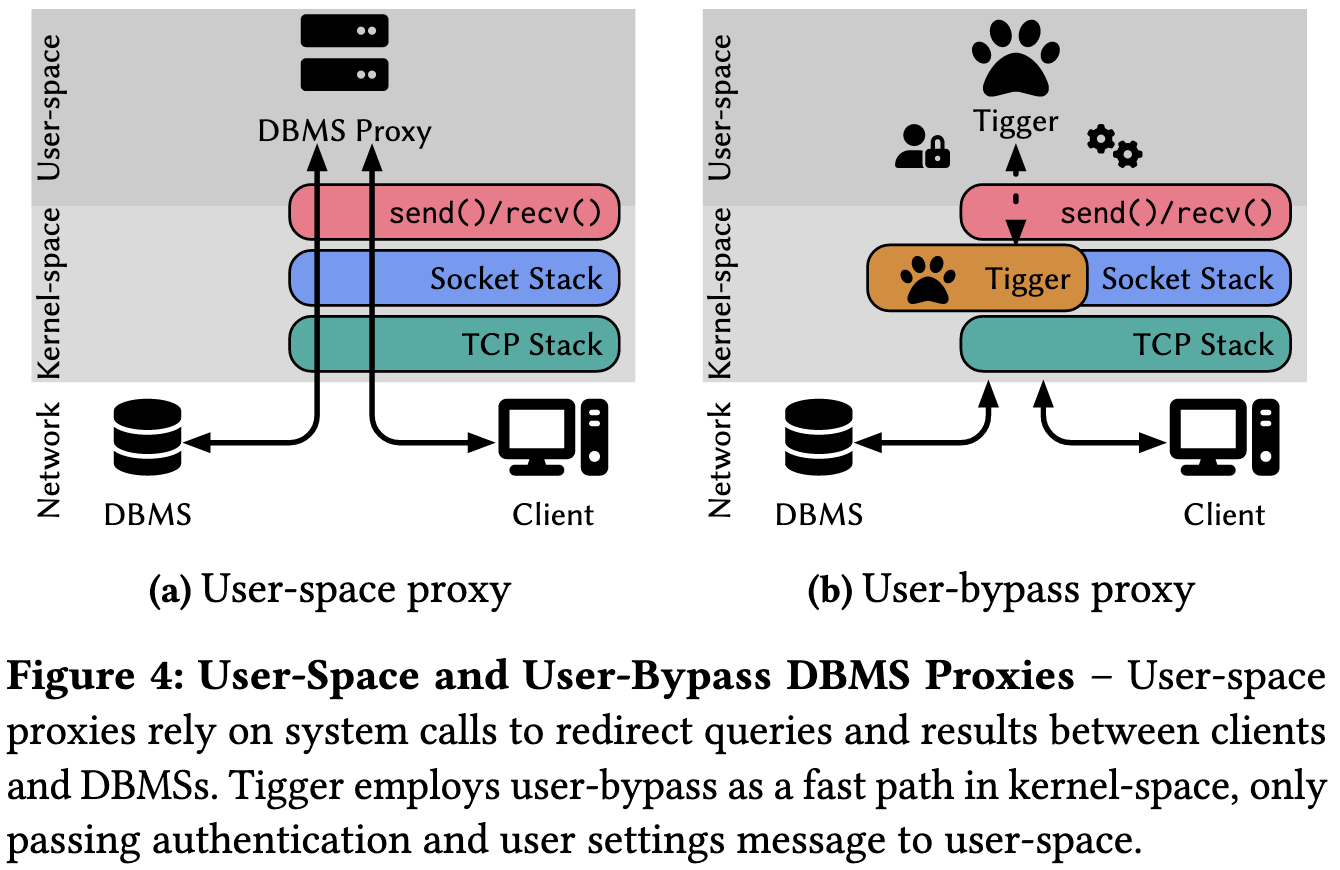
现有的proxy采用的均为图4(a)的架构,采用事件驱动的用户空间应用程序,在身份验证步骤之后,(1) 从网络套接字读取客户端消息,(2) 检查字节流,(3) 将客户端与后端服务器匹配,以及 (4) 在匹配的套接字上发送数据。
改进以后的Tigger可以通过eBPF的方式实现消除send/recv的user与kernel之间的冗余数据拷贝的开销。
具体实现
架构设计
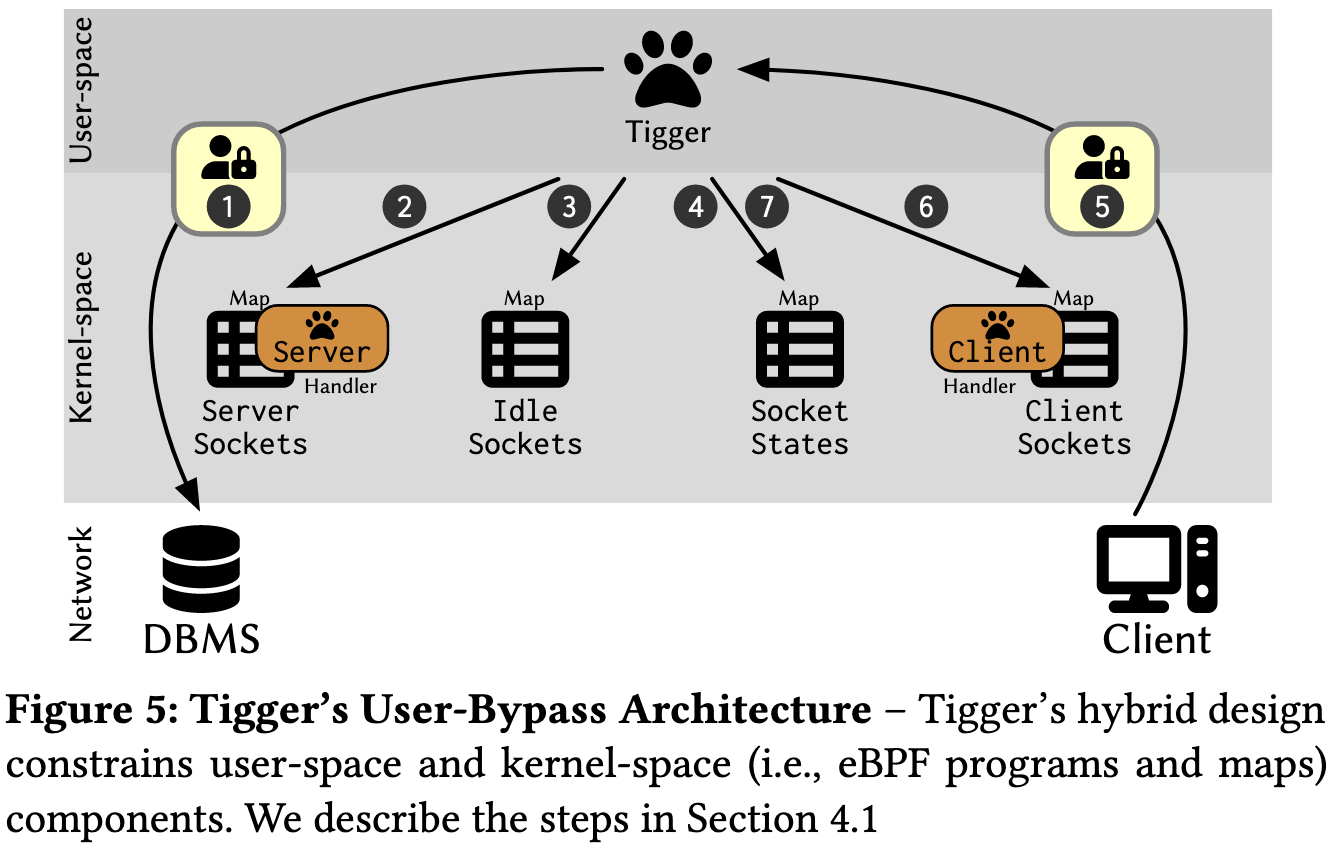
主要步骤流程如下
- 客户端认证
- 将server的socket加入到ServerSocketsMap
| |
- tigger再将其加入IdleSocket
| |
- Tigger会清除当前的socket的metadata
- 直到有新的连接请求到来的时候,会再次经过Userspace的验证
- 再将client的socket加入到ClientSocketsMap,此时Client端的Handler会开始对应Client的buffer执行对应操作
DBMS协议逻辑
当socket的buffer到达的时候,Tigger的Server和Client都会处理Handler的逻辑
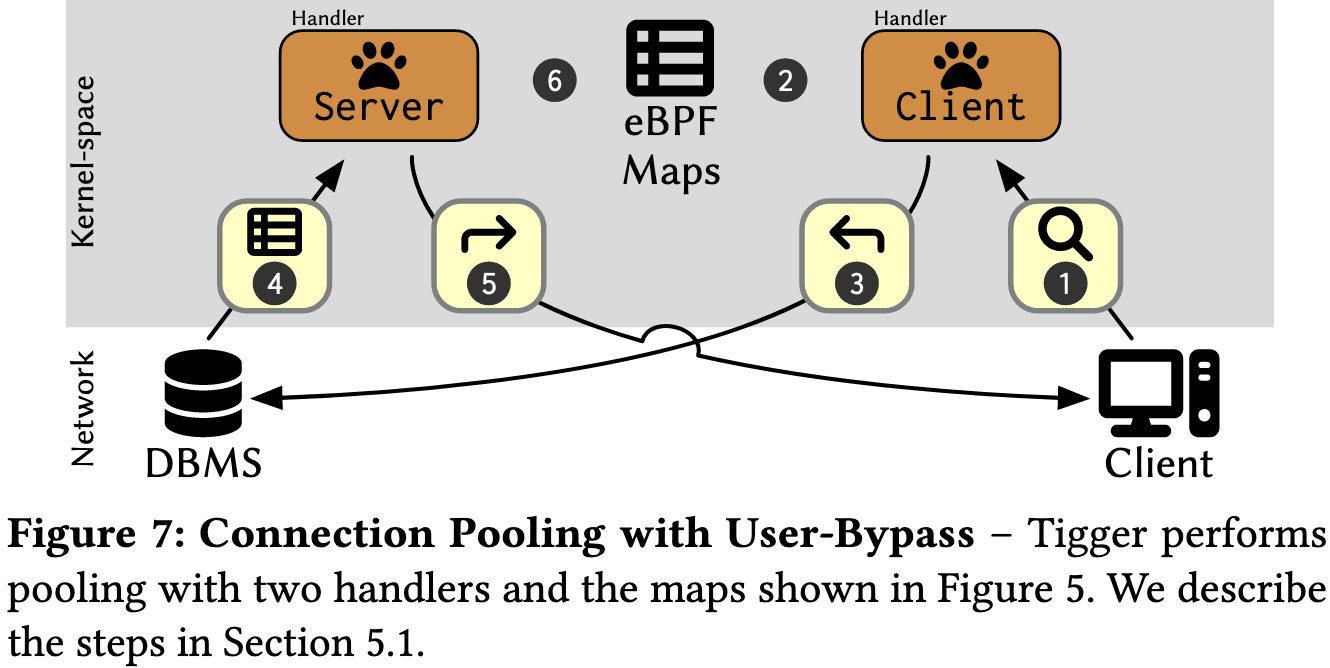
- 当Client提交查询的时候Tigger开始处理
- 先查询SocketStatesMap是否已经存在(存在即表示这个Socket已经被DBMS绑定),如果不存在,则进入slow path
- 在典型情况下,套接字缓冲区包含查询,因此客户端将缓冲区重定向到链接的用户旁路套接字,并更新 SocketStatesMap 中的元数据。
- 后端 DBMS 执行查询并将结果发送回 Tigger。服务器处理程序在缓冲区到达时运行,为后端查找链接的前端套接字。
- 服务器处理缓冲区,将任何中间状态存储在 SocketStatesMap 中,并将缓冲区重定向到链接的 DBMS 套接字。
- 的发生取决于代理的池化模式:在事务完成时进行事务池化或客户端断开连接以进行会话池化。在此步骤中,服务器将取消客户端与 DBMS 的链接,并将后端套接字插入到 IdleSocketsMap 中。
Workload mirroring
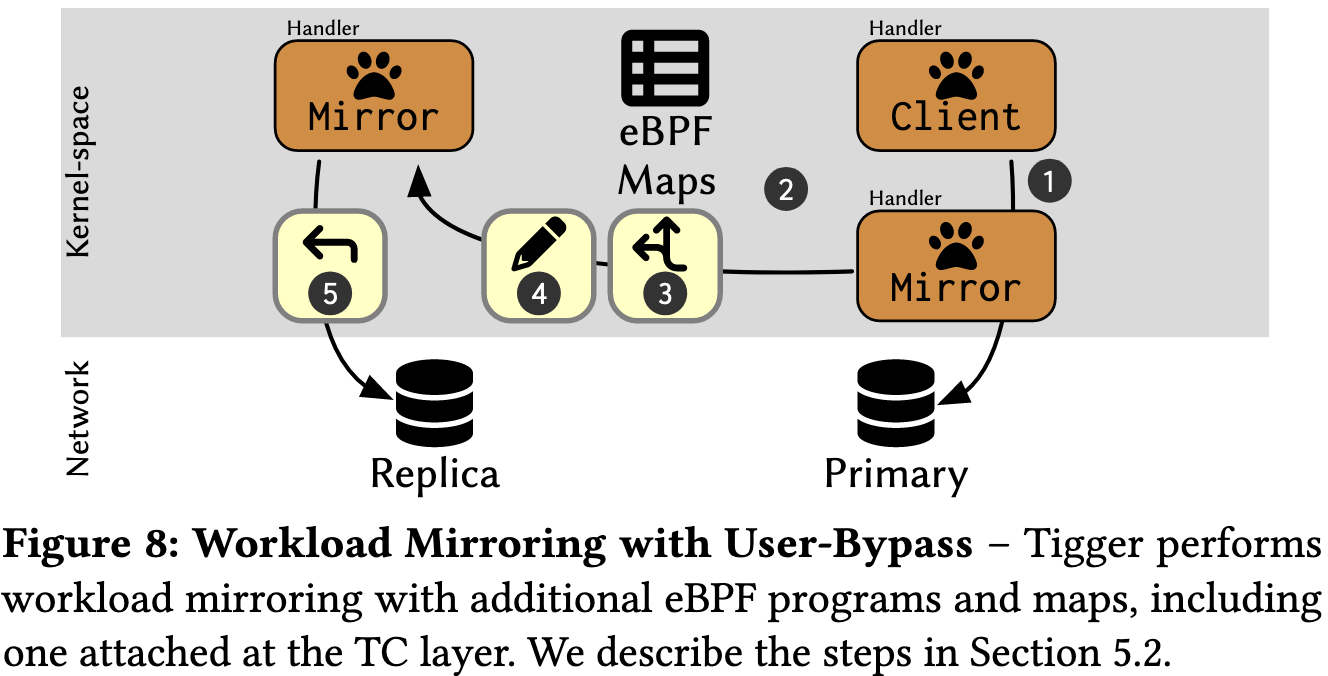
Tigger也支持主从架构,当1.Client发起连接之后,2.Mirror从MirrorSocketMap检查到Destination,并且发送给3.Replica。4.过程会把TCP修改成UDP包。
性能评估
主要对比了No proxy,PgBouncer,Odyssey三个场景。总的来说,包括Serverless、Workload Mirroring、Protocol Efficiency几个角度均有较好的性能提升。
未来工作
考虑兼容更多的数据库协议,使用Linux异步IO库如io_uring,以及SmartNIC的优化工作。
总结
文章的思路idea还是不错的,利用eBPF来实现Proxy在数据库连接池场景下的优化目前工作较少,但是在云计算场景下使用较多。本文代码工作量不算很多,约2000LoC的C程序,主要工作难点在PgBouncer代码的魔改上。