简介
现阶段的无服务框架如 KNative 等,并没有实现良好的数据平面优化,同时需要面临严重的冷启动问题。
本文提出 SPRIGHT,一个轻量级、高性能、响应迅速的无服务器框架。SPRIGHT 利用共享内存处理,通过避免不必要的协议处理和序列化反序列化开销,显著提高了数据平面的可伸缩性。SPRIGHT 通过扩展的 Berkeley 数据包过滤器 (eBPF) 广泛利用事件驱动处理。我们创造性地使用 eBPF 的套接字消息机制来支持共享内存处理,并能够消除冷启动问题。
背景介绍
本文提出了目前 Serverless 主要问题在于以下两点:
- 使用大量的重量级 Serverless 的组件,如每个 pod 的 sidecar,而且一个 container 就对应一个 pod
- 目前函数调用链与数据平面的耦合程度不够高,经常需要使用额外的中间件如 Kafka、Istio 等
本文完成了 gateway,以及零拷贝 message,事件驱动 proxy,function-chain on shared memory 等功能。
函数链的数据管道使用消息路由,如下所示:
- 客户端通过集群的入口网关向消息代理/前端代理发送消息(请求)。
- 消息在消息代理/前端代理中排队并注册为事件。
- 消息代理/前端代理将消息发送到链中头部(第一个)函数的活动 pod,由用户定义。
- 调用函数 pod 来处理传入的请求。在第一个函数处理请求后,将返回一个响应并在消息代理/前端代理中排队,并注册为链中下一个函数的新事件。
- 消息代理/前端代理将此新事件发送到活动 pod,用于链中的下一个函数。
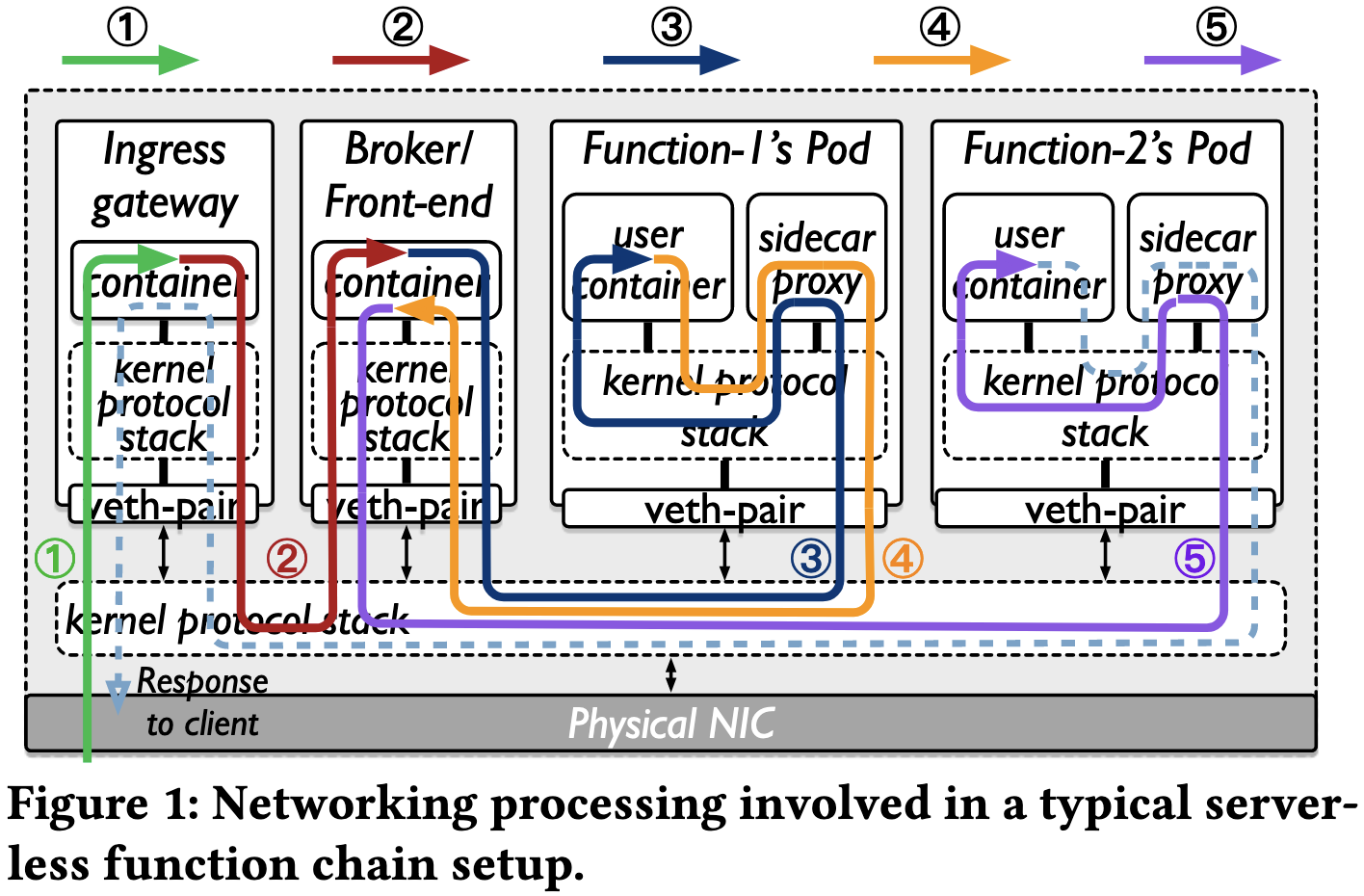
传统流程存在的弊端
- 这一个流程有过多的数据拷贝,上下文切换以及中断,每个请求都有 15 次数据拷贝,15 次上下文切换,25 次中断。
- 过多的协议处理,网络处理。
- 不必要的序列化/反序列化流程。
- Function 的过于复杂的组件,如 Istio 的 Envoy,Knative 的 Queue Proxy,OpenFaaS 的 OF-watchdog。
系统设计
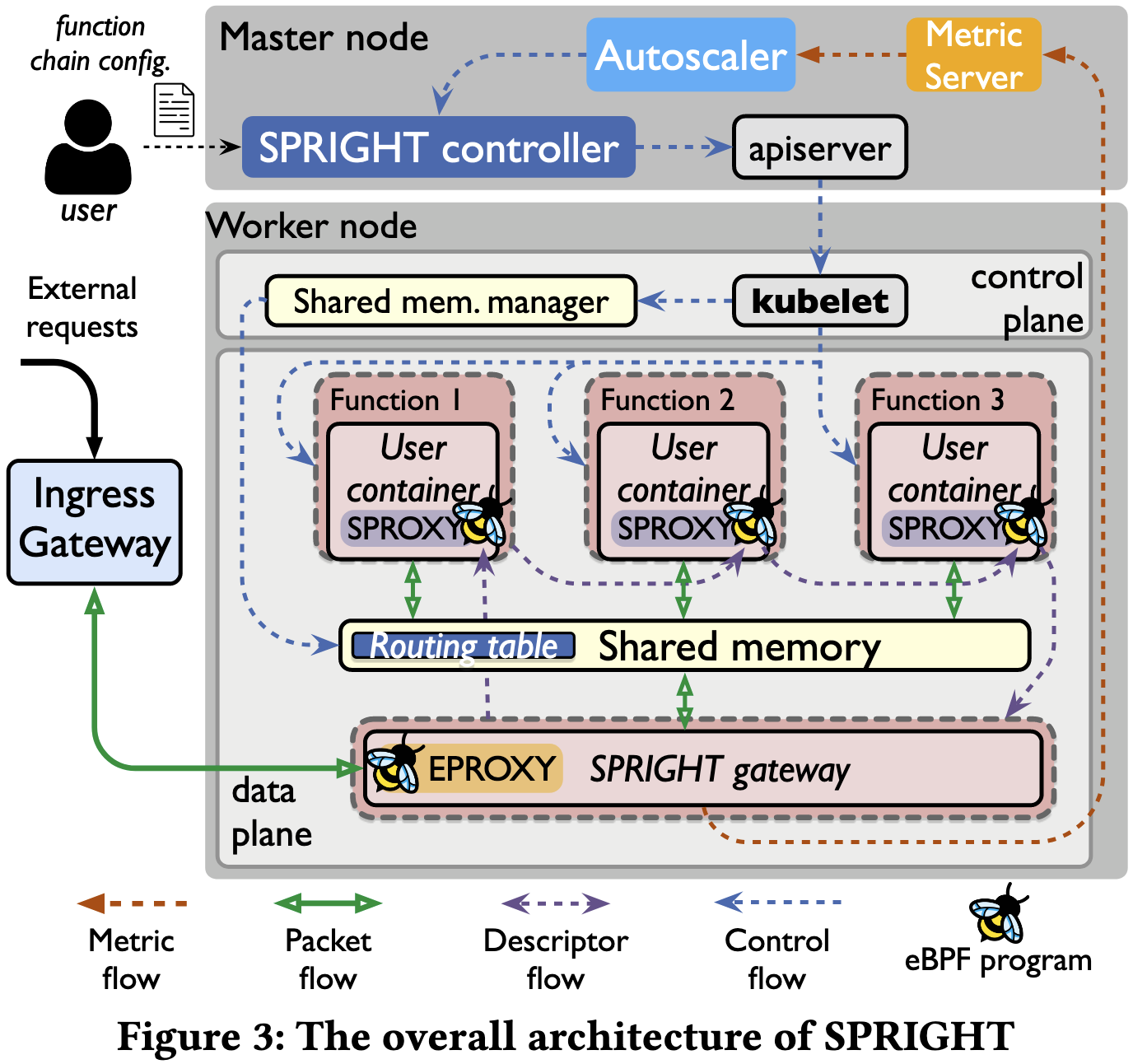
其中 SPRIGHT 的 controller 运行在 k8s 的 master 节点,与 kubelet 协作管理所有 pod 的生命周期。同时也利用 k8s 的 autoscaler and placement engine。
SPRIGHT 会将请求的 payload 分配到一个通用的 shared memory 中,并且保证函数链上的所有函数都分配在同一个节点中,这样可以很好地利用共享内存。
同时 SPRIGHT gateway 也是事件驱动的,不存在过高的 CPU 占用。
Optimizing communication within serverless function chains
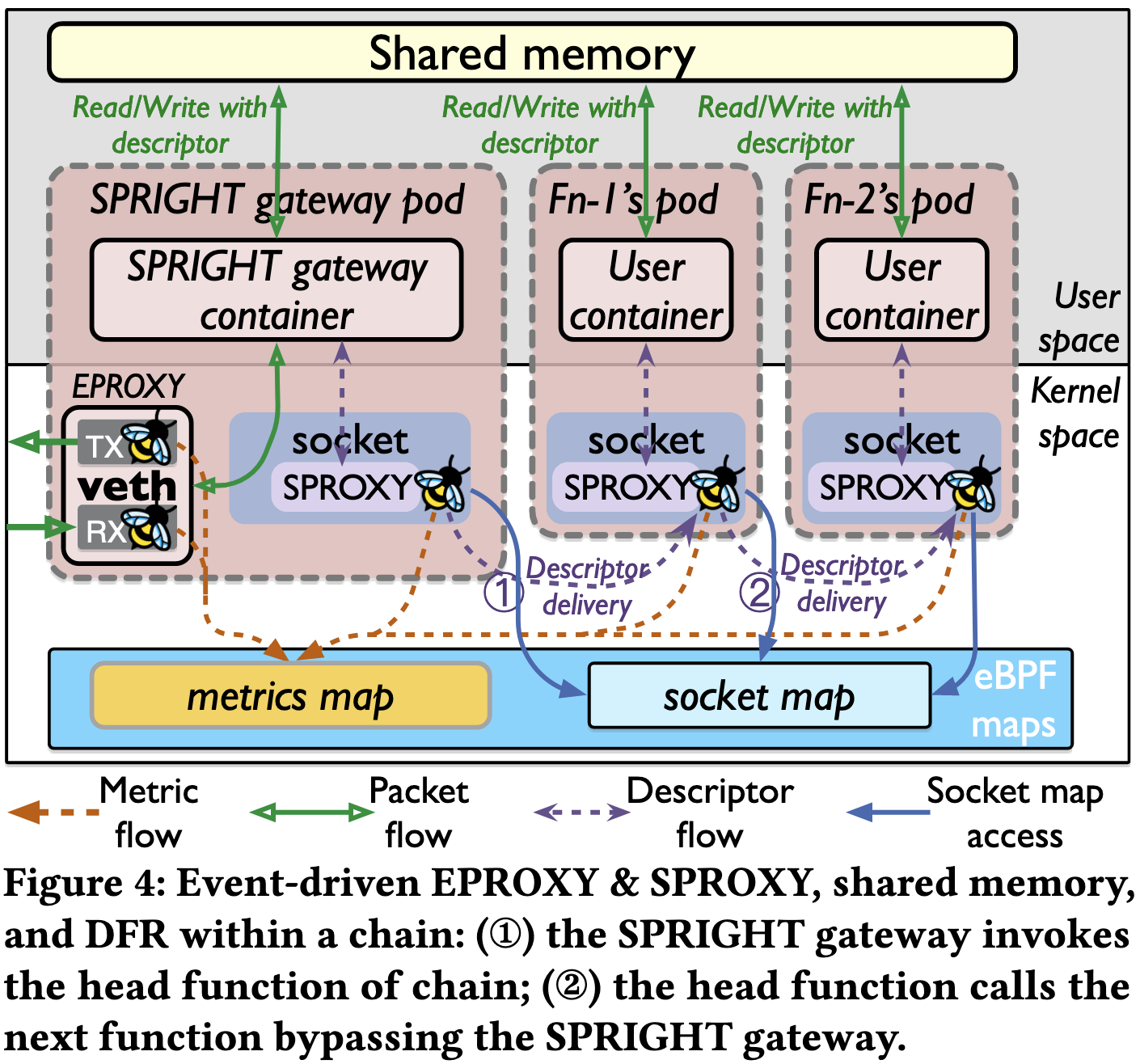
SPRIGHT 为每个请求都分配一个 Linux 大页,在每个 packet descriptor 上都会标注好 HugePage 的位置。
SPROXY 的数据报头只有 16B,一个是下一个函数的实例 ID,一个是共享内存的指针。函数实例 ID 用于在 BPF Map 中查询 socket(当函数实例启动的时候,会在 socket map 中进行注册)。
由于所有函数都是 Direct Function Routing(DFR)的,相较于 Load balancing 场景下有更好的新能更小的通信开销,这个 DFR 调用步骤需要在 SPRIGHT controller 中进行注册。
Security domains in SPRIGHT
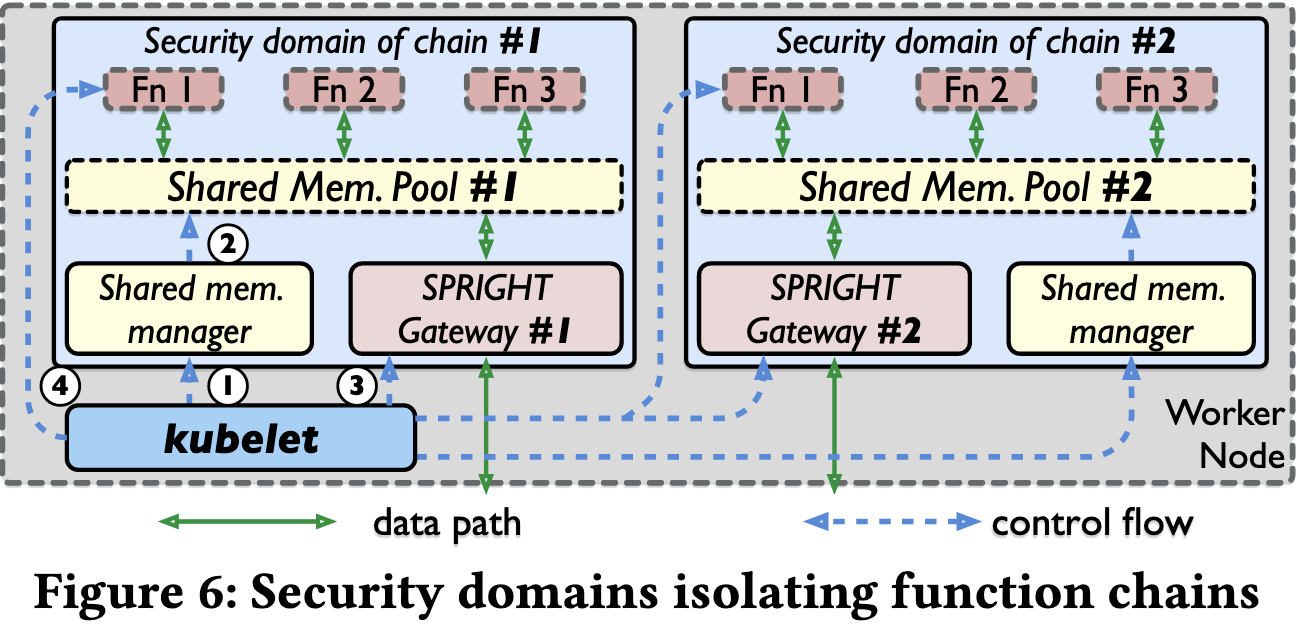
在安全层面考虑,采用了 DPDK 的 API,让每个 shared memory 都有一个特定的文件前缀。利用 SPROXY 的可扩展性来执行函数间消息过滤,即仔细检查哪个函数可以写入和读取每个描述符。接收到描述符后,SPROXY 会在过滤映射(基于 eBPF 映射构建)中执行规则查询,检查该数据包描述符的目的地是否允许。
图 6 显示了 SPRIGHT 中 Function Chain 的启动流程:
- 在收到创建 Function Chain 的请求时,SPRIGHT 控制器会启动专用于该链的共享内存管理器。
- 共享内存管理器初始化链的私有内存池。
- SPRIGHT 控制器为链创建专用的 SPRIGHT 网关。
- SPRIGHT 控制器启动链中的功能,并为每个函数附加一个 SPROXY,同时在 eBPF 映射中配置过滤规则。
eBPF-based dataplane acceleration for external communication
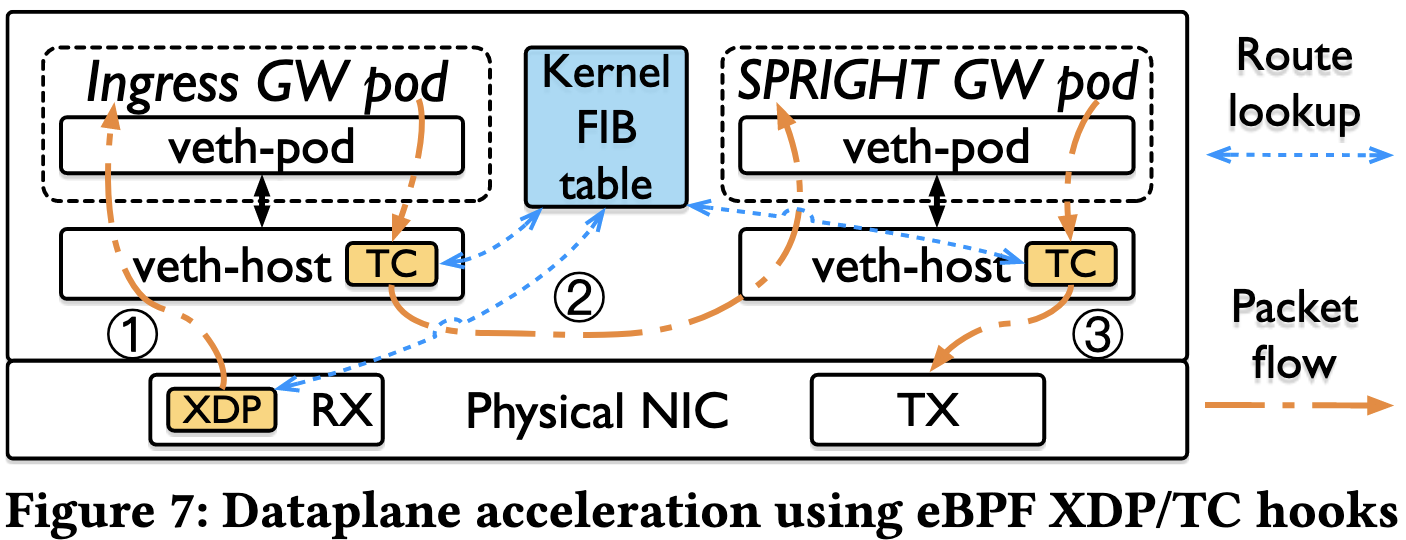
物理网卡上的 XDP 程序处理网卡接收的所有入站数据包。在路由表查找后,它将数据包重定向到目标函数 pod 的 veth-host(图 7 中的 (1))。veth-host 的 TC 程序处理来自函数 pod 的出站数据包。根据数据包的目的地,TC 程序可能采用不同的路由。如果数据包的目的地是同一节点上的另一个功能 pod(例如,入口网关 pod 和 SPRIGHT 网关 pod 之间的流量),则 TC 程序通过“TC_ACT_REDIRECT”直接将数据包传递到目标功能 pod 的 veth-host(图 7 中的 (2))。如果目标函数 pod 位于另一个节点上,则 TC 程序会将数据包重定向到 NIC(图 7 中的 (3))。
总结
基于本文这种方式实现 Function Chain 没有数据拷贝,没有协议处理,也没有序列化/反序列化开销。
缺点:
- 整个 Function Chain 都必须部署在同一个节点上,这样对于异构场景非常难以实现,同时扩缩容也成为问题。
- SPRIGHT 现有的编程模型假设函数的代码在调用后运行到完成,是纯事件驱动的,并且本质上支持函数之间的异步调用。
- 总共代码量约 3500LoC,而且目前只支持 C 语言实现的函数,实用性不高。