简介
采用 eBPF 基于 Memcached 的性能优化。 使用基于 DPDK 的解决方案绕过 Linux 网络堆栈,但此类方法需要完全重新设计软件堆栈,并且即使在客户端负载较低时也会导致 CPU 利用率较高。作为 Memcached 的内核缓存,可在标准网络堆栈执行之前为请求提供服务。对 BMC 缓存的请求被视为 NIC 中断的一部分,这允许性能随着服务于 NIC 队列的核心数量而扩展。为了保证安全,BMC 采用 eBPF 来实现。尽管 eBPF 存在安全限制,但我们证明了实现复杂的缓存服务是可能的。 由于 BMC 运行在商用硬件上,不需要修改 Linux 内核和 Memcached 应用程序,因此可以广泛部署在现有系统上。
系统结构
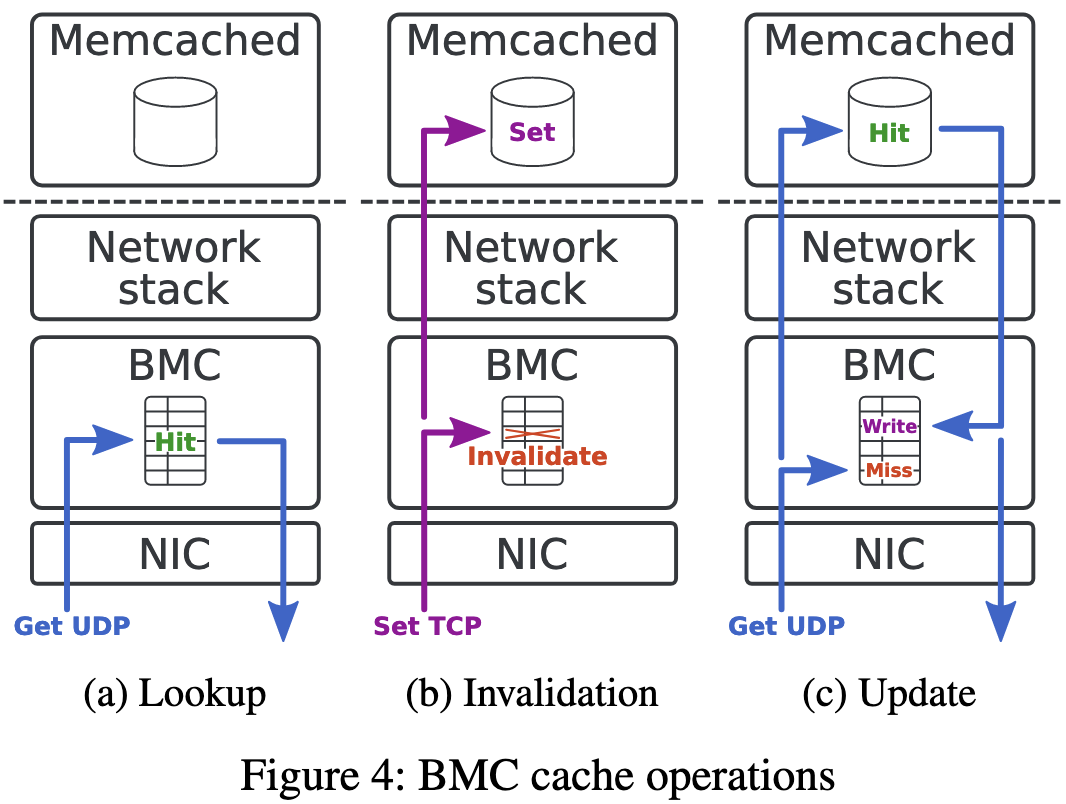
当处理 GET 请求 (4a) 时,BMC 检查其内核缓存,如果找到请求的数据,则发回相应的回复。在这种情况下,包含请求的网络数据包永远不会由标准网络堆栈或应用程序处理,从而释放 CPU 时间。
SET 请求由 BMC 处理以使相应的缓存条目无效,然后传递给应用程序 (4b)。缓存条目失效后,针对相同数据的后续 GET 请求将不会由 BMC 提供服务,而是由 Memcached 应用程序提供服务。 BMC 总是让 SET 请求通过标准网络堆栈,原因有两个。首先,它允许重用操作系统 TCP 协议实现,包括发送确认和重新传输段。其次,它确保 SET 请求始终由 Memcached 应用程序处理,并且应用程序的数据保持最新。我们选择不使用 BMC 拦截的 SET 请求来更新内核缓存,因为 TCP 的拥塞控制可能会在执行后拒绝新的段。而且,使用 SET 请求更新内核缓存需要 BMC 和 Memcached 都以相同的顺序处理 SET 请求,以保持 BMC 缓存的一致性,如果没有过于昂贵的同步机制,这是很难保证的。
当 BMC 缓存发生未命中时,GET 请求将传递到网络堆栈。然后,如果 Memcached 中发生命中,BMC 会拦截传出的 GET 回复以更新其缓存 (4c)。
BMC 可以受益于现代 NIC 功能(例如多队列和 RSS),以便在多个 CPU 内核之间分配处理。同时支持安排到特定 CPU 核心
BMC 缓存设计
BMC 缓存被设计为由 Memcached 键索引的哈希表。它是一种直接映射缓存,这意味着哈希表中的每个桶一次只能存储一个条目。 BMC 使用 32 位 FNV-1a 哈希函数来计算哈希值。由于这是一次对单个字节进行操作的滚动哈希函数,因此它允许 BMC 在解析 Memcached 请求时计算密钥的哈希值。使用取模运算符将哈希值简化为缓存表中的索引。每个缓存条目包含一个有效位、一个哈希值、一个自旋锁、实际存储的数据以及数据的大小。这种缓存设计为查找、插入和删除操作提供了恒定的时间复杂度。为了验证缓存命中,BMC 检查缓存条目的有效位是否已设置以及存储的密钥是 否与处理的请求的密钥相同。
为了避免 eBPF 的极限,BMC 功能逻辑被分为多个小的 eBPF 程序。同时限制了最大的长度 250B。
实现流程
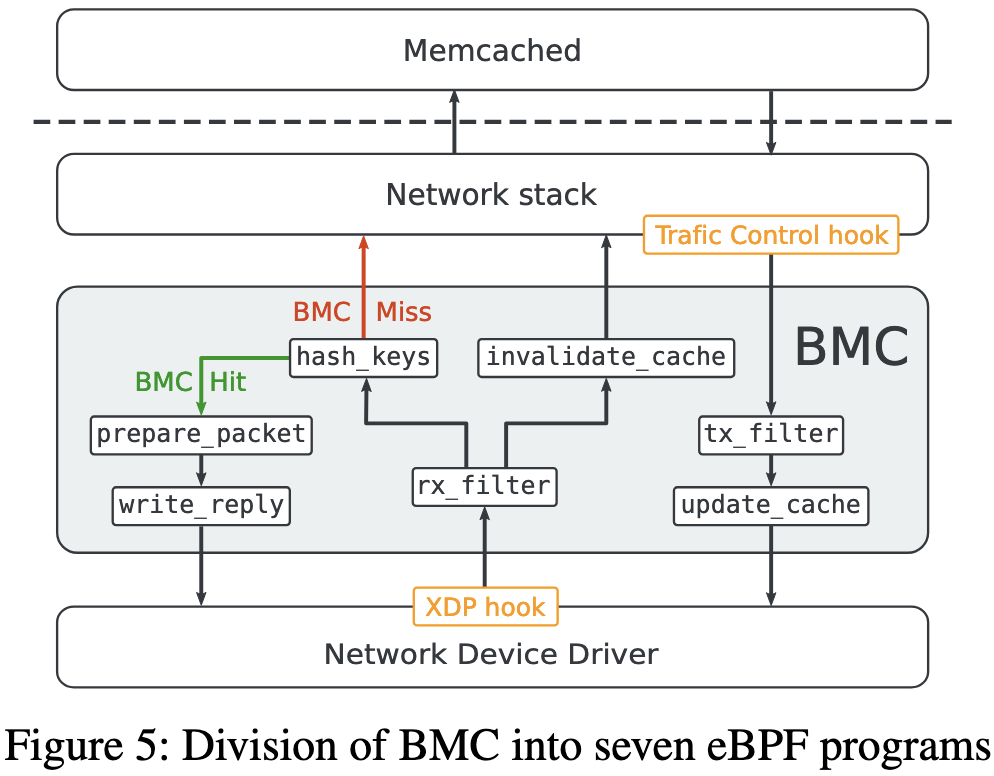
rx_filter. 第一个 eBPF 程序的目标是使用两条规则过滤与 Memcached 流量相对应的数据包。第一条规则匹配 UDP 数据包,其目标端口对应于 Memcached 且其负载包含 GET 请求。第二条规则匹配目标端口也与 Memcached 对应的 TCP 流量。传入链根据规则匹配进行分支。如果两个规则均不匹配,则网络堆栈将照常处理该数据包。
| |
hash_keys 该程序计算数据包中包含的每个 Memcached GET 密钥的哈希值。然后,它检查相应的缓存条目是否有任何缓存命中或哈希冲突,并将已命中的密钥哈希保存在每 CPU 数组中,该数组用于存储链执行的上下文数据。
prepare_packet 该 eBPF 程序增加接收数据包的大小并修改其协议标头以准备响应数据包,交换源和目标以太网地址、IP 地址和 UDP 端口。然后它调用该链分支的最后一个 eBPF 程序。BMC 可以添加到数据包的最大字节数受到网络驱动程序实现的限制。在我们当前的 BMC 实现中,根据 BMC 附加的不同网络驱动程序,该值设置为 128 字节,并且可以增加到更高的值以匹配其他网络驱动程序实现。
write_reply 该 eBPF 程序检索保存在每个 CPU 数组中的密钥哈希,以将相应的缓存条目复制到数据包的有效负载中。如果表包含多个键散列,则此 eBPF 程序可以调用自身来复制响应数据包中尽可能多的项目。最后,传入链的该分支通过将数据包发送回网络而结束。
invalidate_cache 传入链的第二个分支处理 Memcached TCP 流量并包含单个 eBPF 程序。该程序在数据包的有效负载中查找 SET 请求,并在发现使相应缓存条目无效时计算密钥哈希值。传入链的该分支处理的数据包始终传输到网络堆栈,以便 Memcached 可以接收 SET 请求并相应地更新自己的数据。
总结
整个BMC的代码工作量不算大,约1000LoC的C程序,优点是可以不需要修改源程序,直接通过到来的请求判断memcached的target port和payload来进行处理,可以直接部署在现有系统上。
缺点:暂时只支持有限长度的Key/Value。